

在现代 IT 架构中,实时处理连续的业务数据和事件流变得越来越重要。这种类型的架构,其中事件正在构建数据处理的中心,也称为响应式流架构。在下文中,我将展示如何借助工作流技术解决一些相关挑战。
让我们先仔细看看这种类型的架构。基本上,基于事件的数据处理并不新鲜,实际上已经在各个专业领域(例如金融部门)中发展了数十年。但是,自过去几年以来,出现了处理数据流的新标准。像 Apache Kafka, Storm, Flink, or Spark 的日益普及,推动了新的炒作。
从工业生产系统到多人电脑游戏,越来越频繁地使用所谓的流式架构,以便能够实时处理大数据。流媒体架构已经发展成为现代科技公司的核心架构元素。在许多公司中,实时流已成为其架构中的核心系统。
目标是能够更快地集成新的系统解决方案并连接任何类型的数据流。流媒体架构不仅存在于 eBay、Netflix 或亚马逊等技术巨头中,而且在今天,每一家致力于业务流程数字化的现代科技公司都可以使用流媒体架构。那么,构建这样一个架构的主要挑战是什么?
处理数据流
在事件流的早期,数据流被记录并随后进行分析(批处理),实际业务逻辑完全不受影响。但是,随着业务逻辑变得更加复杂,处理数据变得更加困难。因此,处理数据流的一般任务提出了许多不同的挑战。
来自不同来源(Producer)的数据需要进行排序、分类并分派到不同的目标(Consumer)。生产者可以生成不同类型的事件,而消费者通常只对可能由不同消费者创建的特定事件感兴趣。系统必须能够以协调的方式对数据进行分区、结构化和分发。
为了保证高数据吞吐量,此类系统必须水平扩展。与此同时,Apache Kafka已成为此类技术的事实上的标准。它提供了很大的灵活性,并且可以以多种不同的方式集成到其他系统中。
流分析和业务处理
但是,捕获数据流只是挑战的一部分。某些数据处理必须与传入数据同时进行,以便能够迅速将结果用于决策。例如,购物车系统中的产品选择可以触发推荐系统并行执行。这种类型的需求在流架构中创建了另一个构建块——称为流分析。
有时,来自数据流的单个事件足以触发预定义的业务逻辑。但是,通常需要能够识别不同事件之间的联系,以便运行能够产生实际业务价值的高级业务流程。通过在给定的时间段内累积它们,可以在时移的相似事件之间建立这种联系。例如,在线商店系统中对某种产品的短期需求增加可能会触发额外生产线的启动。在其他情况下,可能需要关联某些不同类型的事件并合并数据以触发相应的业务流程。这些方法也称为Windowing和 Joining。
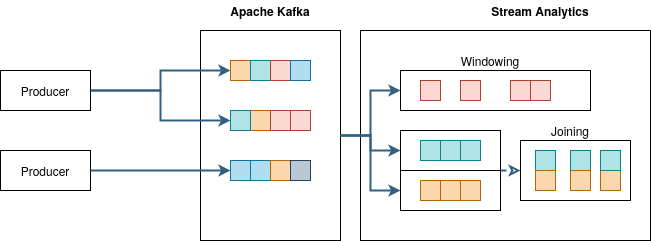
在所有这些情况下,都会实施所谓的微批次来运行流分析模块内的业务逻辑。Apache Kafka Streams是Kafka-Stack 中的一个扩展,提供了许多这些功能。它允许使用不同的编程语言(如 Java 或 Scala)开发微批次。在JavaSpektrum 杂志2021/03版本中之前,来自 Siemens AG 的 George Mamaladze 用更广泛的方法描述了这个概念。
然而,微批处理带来了新的挑战。业务逻辑不能再用简单的功能来描述了。例如,需要有状态算法来保持一段时间内的数据聚合。另一个要求是这些算法的并行执行与相应的状态管理。因此,有必要保留这些状态,并在出现错误时在上次中断的点恢复业务流程。这种业务逻辑的实现很复杂,而且通常很耗时。
为了能够管理更复杂的长期运行的业务流程,工作流引擎成为实现数据流和业务逻辑分离的重要构建块。工作流引擎在处理复杂业务逻辑和长期保持业务状态方面进行了优化。主要区别在于所有正在运行的微批次的状态管理。工作流引擎的模型驱动架构允许快速适应不断变化的需求和技术。
基于新的传入事件(由 Micro-Batch 创建),工作流引擎可以启动新的业务流程或继续已启动的流程实例。工作流引擎将自动持久化业务流程的状态,并可以从不同的生产者收集事件。然而,单个处理步骤的结果或业务流程的完成也可能产生新事件。
所以,一个内无流架构,将工作流引擎需要的角色消费者和生产者控制业务流程的整个生命周期。

使用 Imixs-Workflow 进行流分析
Imixs-Workflow是一个开源工作流引擎,提供广泛的功能来控制复杂的业务流程。基于事件的工作流引擎可以作为微服务运行,并且可以通过其微内核架构进行扩展。Imixs-Workflow 已经带有一个 Apache Kafka 适配器,它可以很容易地从响应式流媒体平台开始处理事件。
所述 Imixs-Kafka Adapter 充当卡夫卡堆栈内产生的事件的一个消费者。凭借其 Autowire 功能,Imixs-Workflow 还可以在处理生命周期中自动发送工作流消息。这允许在分布式微服务架构中构建更复杂的业务流程。
模型驱动的业务逻辑
业务流程建模符号 (BPMN)——当今业务流程建模的标准——可以帮助以模型驱动的方式构建灵活的架构。BPMN 2.0 是一种基于 XML 的可扩展建模标准,允许对复杂的业务流程进行建模、分析和执行。
在像 Imixs-Workflow 这样的基于事件的工作流引擎中,业务流程的不同状态被描述为Tasks。从一种状态到下一种状态的转换由事件元素描述。事件可以通过使用 Kafka 流事件触发,也可以由外部服务或人类参与者触发。通过将任务和事件与网关元素相结合,可以对业务规则进行建模,以根据收集到的数据做出决策并对不同情况做出反应。
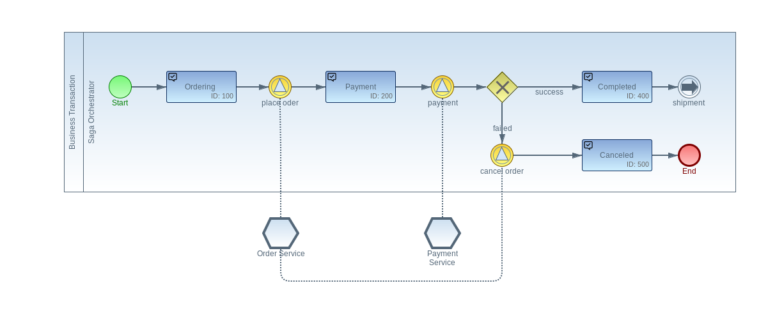
聚合流事件
使用工作流引擎使用事件流的优点是能够在特定上下文中长时间聚合数据。数据可以从不同来源聚合和转换,并与现有业务数据相结合。
例如,在购物系统中,新客户的注册可以触发 VIP 会员流程。工作流引擎首先仅对新客户注册做出反应,以启动 VIP 会员业务流程。从这一刻起,工作流引擎会对购物系统中启用 VIP 会员资格的某些事件做出反应。例如,这可以是购买某些产品或订阅。
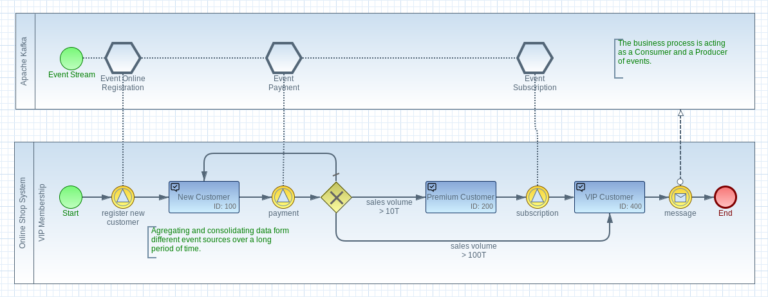
更改业务逻辑不需要对代码库进行任何更改或实现新的微批次。此外,可以在运行时调整新的附加业务工作流,而无需更改架构。
人工智能
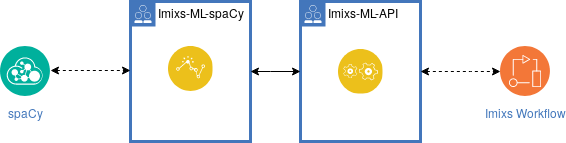
基于 Imixs 微内核架构,可以使用提供附加功能的各种适配器或插件模块来扩展业务流程。例如,Imixs-ML 适配器提供了一个通用 API 来集成各种 ML 框架,如 spaCy 或 Apache mxnet。借助这种适配器技术,可以通过人工智能丰富业务处理。
Imixs-ML 的核心概念基于自然语言处理 (NLP),它是机器学习的一个子领域。使用命名实体识别 (NER),可以分析给定的文本流,并且可以从任何类型的流事件中提取文本实体,例如人员、地点,甚至发票数据(例如日期和发票总额)。这种机器学习过程的结果可用于对更复杂的业务逻辑进行建模,并基于各种训练模型进行业务讨论。
持续学习
持续学习是 ML 训练模型从数据流中持续学习的能力。在实践中,这意味着支持模型在新数据进入时自主学习和适应生产的能力。通过 Imixs-ML 适配器,这个概念被集成到业务流程的实时周期中。Imixs-Workflow 引擎可以根据业务流程的结果自动优化 ML 训练模型。通过这种方式,来自事件流平台的数据可用于生成新的训练模型以供未来处理。但人工操作员做出的决定也可用于改进现有的 ML 训练模型。
结论
通过将反应式流架构与现代业务流程管理的概念相结合,可以在很短的时间内实现高度复杂的业务流程。得益于基于现代 BPMN 2.0 的工作流技术的模型驱动方法,即使是复杂的业务流程也可以在不改变整体架构的情况下设计和执行。这种类型的架构为处理连续数据流开辟了全新的可能性。



